-
- abstol
This variable sets the absolute error tolerance used in convergence
testing branch currents.
| Default |
Min Value |
Max Value |
Set From |
|---|
| 1e-12 |
1e-15 |
1e-9 |
Simulation Options/Tolerance |
- chgtol
This variable sets the minimum charge used when predicting the time
step in transient analysis.
| Default |
Min Value |
Max Value |
Set From |
|---|
| 1e-14 |
1e-16 |
1e-12 |
Simulation Options/Timestep |
- dcmu
This option variable takes a value of 0.0-0.5, with the default being
0.5. It applies during operating point analysis. When set to a value
less than 0.5, the Newton iteration algorithm mixes in some of the
previous solution, which can improve convergence. The smaller the
value, the larger the mixing. This gives the user another parameter
to twiddle when trying to achieve dc convergence.
| Default |
Min Value |
Max Value |
Set From |
|---|
| 0.5 |
0.0 |
0.5 |
Simulation Options/Convergence |
- defad
This variable sets the default value for MOS drain diffusion area, and
applies to all MOS device models.
| Default |
Min Value |
Max Value |
Set From |
|---|
| 0.0 |
0.0 |
1e-3 |
Simulation Options/Devices |
- defas
This sets the default value for MOS source diffusion area, and applies
to all MOS device models.
| Default |
Min Value |
Max Value |
Set From |
|---|
| 0.0 |
0.0 |
1e-3 |
Simulation Options/Devices |
- defl
This sets the default value for MOS channel length, and applies to all
MOS device models. The default is model dependent, and is 100.0
microns for MOS levels 1-3 and 6, and typically 5.0 microns for other
models.
| Default |
Min Value |
Max Value |
Set From |
|---|
| |
0.0 |
1e4 |
Simulation Options/Devices |
- defw
This variable sets the default value for MOS channel width, and
applies to all MOS device models. The default is model dependent, and
is 100.0 microns for MOS levels 1-3 and 6, and typically 5.0 microns
for other models.
| Default |
Min Value |
Max Value |
Set From |
|---|
| |
0.0 |
1e4 |
Simulation Options/Devices |
- delmin
This can be used to specify the minimum internal time step alowed
during transient analysis. When a convergence fails, the internal
time step is reduced, and a solution is attempted again. If repeated
failures drop the internal timestep below delmin, the run will
abort with a ``timestep too small'' message.
If this variable is not set or set to 0.0, WRspice will use 1e-6*tmax. The tmax is the maximum internal timestep
which can be specified in the transient analysis specification (.tran syntax), or defaults to tstep, the transient user
timestep.
| Default |
Min Value |
Max Value |
Set From |
|---|
| 0.0 |
0.0 |
1.0 |
Simulation Options/Timestep |
It may be counterintuitive, but using a larger delmin may avoid
nonconvergence. The matrix elements for reactive terms have the time
delta in the denominator, thus these become large for small delta.
when delta becomes too small, the matrix elements may become so large
that solutions lose accuracy and won't converge. On non-convergence,
the time delta is cut, making matters worse and leading to a "timestep
too small" error and termination of analysis.
- dphimax
This variable sets the maximum allowable phase change of sinusoidal
and exponential sources between internal time points in transient
analysis.
Consider a circuit consisting of a sinusoidal voltage source driving a
resistor network. The internal transient time steps are normally
determined from a truncation error estimation from the numerical
integration of reactive elements. Since there are no such elements in
this case, a large, fixed time step is used. This may not be
sufficient to reasonably define the sinusoidal source waveform, so the
timestep is cut. This variable sets the time scale for the cut. The
default value of 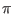 /5
provides about 10 points per cycle. All of
the built-in source functions that are exponential or sinusoidal
reference this variable in the timestep cutting algorithm.
/5
provides about 10 points per cycle. All of
the built-in source functions that are exponential or sinusoidal
reference this variable in the timestep cutting algorithm.
This variable also limits the transient time step when Josephson
junction devices are present, i.e., it is equivalent to the jjdphimax variable in Jspice3.
| Default |
Min Value |
Max Value |
Set From |
|---|
| /5
|
/1000
|
|
Simulation Options/Timestep |
- gmax
The diagonal elements of the circuit matrix are limited to be no
larger than a value, which can be set with the gmax option. No
normal circuit elements will have conductance near this value, however
during iterative solving, large values may be produced by some device
models. This can cause non-convergence or the matrix may become
singular. By limiting the matrix elements, the problem is avoided.
| Default |
Min Value |
Max Value |
Set From |
|---|
| 1e3 |
1e-3 |
1e6 |
Simulation Options/Convergence |
- gmin
This sets the value of gmin, the minimum conductance allowed by the
program.
| Default |
Min Value |
Max Value |
Set From |
|---|
| 1e-12 |
1e-18 |
1e-6 |
Simulation Options/Tolerance |
- maxdata
This variable sets the maximum allowable memory stored as plot data
during an analysis, in kilobytes. The default is 256000. For all
analyses except transient with the steptype variable set to
``nousertp'', the run will abort at the beginning if the memory
would exceed the limit. Otherwise, the run will end when the limit is
reached.
| Default |
Min Value |
Max Value |
Set From |
|---|
| 256000 |
1e3 |
2e9 |
Simulation Options/General |
- minbreak
This sets the minimum interval between breakpoints in transient
analysis. If this variable is not set or set to 0.0, WRspice will
use a value of 5e-8*maxStep, where maxStep may be
specified in the transient analysis initiation (.tran syntax),
or defaults to (endTime - startTime)/50.
| Default |
Min Value |
Max Value |
Set From |
|---|
| 0.0 |
0.0 |
1.0 |
Simulation Options/Timestep |
- pivrel
This variable sets the relative ratio between the largest column entry
and an acceptable pivot value. In the numerical pivoting algorithm
the allowed minimum pivot value is determined by
epsrel = MAX(pivrel*maxval, pivtol)
where maxval is the maximum element in the column where a pivot
is sought (partial pivoting).
| Default |
Min Value |
Max Value |
Set From |
|---|
| 1e-3 |
1e-5 |
1.0 |
Simulation Options/Tolerance |
- pivtol
This variable sets the absolute minimum value for a matrix entry to be
accepted as a pivot.
| Default |
Min Value |
Max Value |
Set From |
|---|
| 1e-13 |
1e-18 |
1e-9 |
Simulation Options/Tolerance |
- rampup
When set to a value dt, during transient analysis all source
values are effectively multiplied by pwl(0 0 dt 1).
That is, all sources ramp up from zero, and assume their normal values
at time = dt.
The dc operating point calculation (if uic is not given)
becomes trivial with all sources set to zero.
This is mostly intended for Josephson junction circuits so constant
valued sources can be used without convergence problems.
| Default |
Min Value |
Max Value |
Set From |
|---|
| 0.0 |
0.0 |
1.0 |
Simulation Options/Convergence |
- reltol
This sets the relative error tolerance used in convergence testing.
| Default |
Min Value |
Max Value |
Set From |
|---|
| 1e-3 |
1e-8 |
1e-2 |
Simulation Options/Tolerance |
- resmin
This is the smallest absolute value of a resistor, smaller given
values are set to this value, preserving sign.
| Default |
Min Value |
Max Value |
Set From |
|---|
| 1e-3 |
1e-5 |
10 |
Simulation Options/Devices |
- temp
This variable specifies the assumed operating temperature of the
circuit under simulation.
| Default |
Min Value |
Max Value |
Set From |
|---|
| 25 |
-273.15 |
1e3 |
Simulation Options/Temperature |
- tnom
The tnom variable sets the nominal temperature. This is the
temperature at which device model parameters are assumed to have been
measured.
| Default |
Min Value |
Max Value |
Set From |
|---|
| 25 |
-273.15 |
1e3 |
Simulation Options/Temperature |
- trapratio
This controls the ``sensitivity'' of the trapezoid integration
convergence test, as described with the trapcheck variable.
Higher values make the test less sensitive (and effective) but reduce
the number of false positives that can slow down simulation.
| Default |
Min Value |
Max Value |
Set From |
|---|
| 10.0 |
2.0 |
100.0 |
Simulation Options/Timestep |
- trtol
This is a factor used during time step prediction in transient
analysis. This parameter is an estimate of the factor by which
WRspice overestimates the actual truncation error. Larger values
will cause WRspice to attempt larger time steps.
| Default |
Min Value |
Max Value |
Set From |
|---|
| 7.0 |
1.0 |
20.0 |
Simulation Options/Timestep |
- vntol
This variable sets the absolute voltage error tolerance used in
convergence testing.
| Default |
Min Value |
Max Value |
Set From |
|---|
| 1e-6 |
1e-9 |
1e-3 |
Simulation Options/Tolerance |
- xmu
This is the trapezoid/Euler mixing parameter that was provided in
SPICE2, but not in SPICE3. It effectively provides a mixture of
trapezoidal and backward Euler integration, which can be useful if
trapezoid integration produces nonconvergence. It applies only when
trapezoidal integration is in use, and the maximum order is larger
than 1. When xmu is 0.5 (the default), pure trapezoid
integration is used. If 0.0, pure backward-Euler (rectangular)
integration is used, but the time step predictor still uses the
trapezoid formula, so this will not be the same as setting maxord to 1 (which also enforces backward-Euler integration).
Trapezoidal integration convergence problems can sometimes be solved
by setting xmu to values below 0.5. Setting xmu below
about 0.4 is not recommended, better to use Gear integration.
| Default |
Min Value |
Max Value |
Set From |
|---|
| 0.5 |
0.0 |
0.5 |
Simulation Options/Timestep |